Как мы отмечали, база данных System R располагается в одном или нескольких сегментах внешней памяти. Каждый сегмент состоит из страниц данных и страниц индексной информации. Размер страницы данных в сегменте может быть выбран равным либо 4, либо 32 килобайтам; размер страницы индексной информации равен 512 байтам. Кроме того, при работе RSS поддерживается дополнительный набор данных для ведения журнала. Для повышения надежности журнала (а это наиболее критичная информация; при ее потере восстановление базы данных после сбоев невозможно) этот набор данных дублируется на двух внешних носителях.
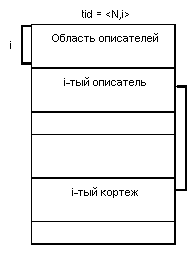
В каждой странице данных хранятся кортежи одного или нескольких отношений. Фундаментальным понятием RSS является идентификатор кортежа (tuple identifier - tid). Гарантируется неизменяемость tid'а во все время существования кортежа в базе данных независимо от перемещений кортежа внутри страницы и даже при перемещении кортежа в другую страницу. Реально tid представляет собой пару <номер страницы, индекс описателя кортежа в странице>. При этом кортеж может реально располагаться в данной странице:
или в другой странице:
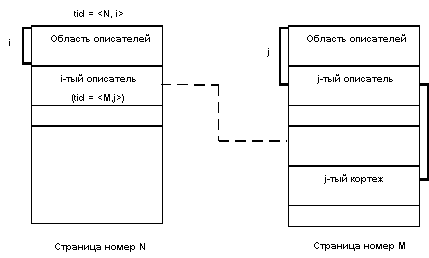
Во втором случае описатель кортежа содержит не координаты кортежа в данной странице, а tid, указывающий на реальное положение кортежа в другой странице. Легко видеть, что применение такого подхода позволяет ограничиться максимум одним уровнем косвенности.
Поскольку допускается нахождение в одной странице данных кортежей разных отношений, каждый кортеж должен, кроме содержательной части, включать служебную информацию, идентифицирующую отношение, которому принадлежит данный кортеж. Кроме того, в System R (точнее, в языке SQL) допускается динамическое добавление полей к существующим отношениям. При этом реально происходит лишь модификация описателя отношения в отношении-каталоге отношений. В существующем кортеже отношения новое поле возникает только при модификации этого кортежа, затрагивающей новое поле. Это позволяет избежать массовой перестройки хранимого отношения при добавлении к нему новых полей, но, естественно, требует хранения при кортеже дополнительной служебной информации, определяющей реальное число полей в данном кортеже. (Заметим, что удалять существующие поля существующего отношения в SQL System R не разрешается).
На основе наличия неизменяемых во время существования кортежей tid'ов в System R поддерживаются дополнительные управляющие структуры - индексы. Каждый индекс определен на одном или нескольких полях отношения, значения которых составляют его ключ, и позволяет производить прямой поиск по ключу кортежей (их tid'ов) и последовательное сканирование отношения по индексу, начиная с указанного ключа, в порядке возрастания или убывания значений ключа. Некоторые индексы при их создании могут обладать атрибутом уникальности. В таком индексе не допускаются дубликаты ключа. Это единственное средство SQL указания системе первичного ключа отношения (фактически, набора первичного и всех альтернативных ключей отношения).
Для организации индексов в System R применяется техника B-деревьев. Каждый индекс занимает отдельный набор страниц, номер корневой страницы запоминается в описателе индекса. Использование B-деревьев позволяет достичь эффективности при прямом поиске, поскольку они в силу своей сильной ветвистости обладают небольшой глубиной. Кроме того, B-деревья сохраняют порядок ключей в листовых блоках иерархии, что позволяет производить последовательное сканирование отношения в порядке возрастания или убывания значений полей, на которых определен индекс. Фундаментальное свойство B-деревьев - автоматическая балансировка дерева - допускает произведение лишь локальных модификаций индекса при переполнениях и опустошениях страниц индекса. (Мы достаточно вольно используем здесь термин B-дерево. На самом деле в System R используется модифицированный по сравнению с исходным вариант B-деревьев, который называют B*-, а иногда B+-деревьями). В самих B-деревьях System R ничего особенного нет; более подробно мы на этом останавливаться не будем. Отметим только, что System R, насколько нам известно, была первой системой, в которой для организации индексов использовались B-деревья. Эту традицию соблюдает большинство реляционных систем, возникших после System R.
Видимо, наиболее важной особенностью физической организации баз данных в System R является возможность обеспечения кластеризации связанных кортежей одного или нескольких отношений. Под кластеризацией кортежей понимается физически близкое расположение (в пределах одной страницы данных) логически связанных кортежей. Обеспечение соответствующей кластеризации позволяет добиться высокой эффективности системы при выполнении выделенного класса запросов. В силу большой важности понятия кластеризации в System R и ее развитиях рассмотрим историю вопроса более подробно.
В окончательном варианте System R существует только одно средство определения условий кластеризации отношения - объявить до заполнения отношения один (и только один) индекс, определенный на полях этого отношения, кластеризованным. Тогда, если заполнение отношения кортежами производится в порядке возрастания или убывания значений полей кластеризации (в зависимости от атрибутики индекса), система физически располагает кортежи в страницах данных в том же порядке. Кроме того, в каждой странице данных кластеризованного отношения оставляется некоторое резервное свободное пространство. При последующих вставках кортежей в такое отношение система стремится поместить каждый кортеж в одну из страниц данных, в которых уже находятся кортежи этого отношения с такими же (или близкими) значениями полей кластеризации. Естественно, что поддерживать идеальную кластеризацию отношения можно только до определенного предела, пока не исчерпается резервная память в страницах. Далее этого предела степень кластеризации отношения начинает уменьшаться, и для восстановления идеальной кластеризации отношения требуется физическая реорганизация отношения (ее можно произвести средствами SQL).
Очевидным преимуществом кластеризации отношения является то, что при последовательном сканировании кластеризованного отношения с использованием кластеризованного индекса потребуется ровно столько чтений страниц данных с внешней памяти, сколько страниц занимают кортежи этого отношения. Следовательно, при правильно выбранных критериях кластеризации запросы, связанные с заданием условий на полях кластеризации можно выполнить почти оптимально.
В ранних версиях System R существовал еще один способ физического доступа к кортежам отношения и, соответственно, еще один способ указания условия кластеризации с использованием так называемых связей (links). На уровне физического представления связь - это физическая ссылка (tid) из одного кортежа на другой (не обязательно одного отношения). В языке SEQUEL (до того момента, когда его стали называть SQL) существовали средства определения связей в иерархической манере: можно было объявить некоторое отношение родительским по отношению к тому же или другому отношению-потомку. При этом указывались поля родительского отношения и отношения-потомка, в соответствии со значениями которых образовывалась иерархия. Правила построения были очень простыми - проводились связи между кортежем родительского отношения ко всем кортежам отношения-потомка с теми же значениями полей связывания. На самом деле, все кортежи отношения-потомка с общим значением полей связывания образовывали кольцевой список, на который проводилась одна связь из соответствующего кортежа родительского отношения. Естественно, от отношения-родителя требовалась уникальность по отношению к значениям полей связывания.
Следует заметить, что мы описали способ использования механизма связей, который поддерживался в ранних версиях SEQUEL. В интерфейсе RSS System R этого периода допускалась возможность произвольного проведения связей без учета совпадения значений полей связывания. Тем самым, в системе в целом не использовались все возможности RSS, которые с избытком превосходили потребности организации иерархических бинарных связей по совпадению полей связывания.
Для одного отношения допускалось создание многих связей: кортеж отношения мог быть родителем нескольких иерархий и входить в несколько других иерархий в качестве потомка. При этом одна связь могла быть объявлена кластеризованной. Тогда система стремилась поместить в одну страницу данных все кортежи одной иерархии. При этом, естественно, использовалась возможность размещения в одной странице данных кортежей нескольких отношений. Основной смысл такой кластеризации заключался в возможности оптимизации выполнения некоторых запросов, включающих (экви)соединение двух связанных отношений в соответствии со значениями полей связывания.
В более поздних публикациях по System R упоминания о механизме связей исчезли, из чего можно заключить, что разработчики отказались от его использования. Думается, что основными причинами отказа от использования связей были следующие. Во-первых, средства построения связей, обеспечиваемые RSS, были очень низкого уровня, гораздо более низкого, чем средства поддержания индексов. Если при занесении кортежа RSS обеспечивала автоматическую коррекцию всех индексов, то для коррекции связей требовалось выполнить ряд дополнительных обращений к RSS, из-за чего время выполнения операции занесения кортежа, конечно, увеличивалось (то же касается операций удаления и модификации кортежа). Во-вторых, при реализации этого механизма, возникают дополнительные синхронизационные проблемы нижнего уровня (уровня совместного доступа к страницам данных). В частности, наличие прямых ссылок между страницами данных увеличивает вероятность возникновения синхронизационных тупиков. Наконец, в-третьих, все эти дополнительные накладные расходы не окупались предоставляемыми механизмом связей преимуществами. Действительно, максимального эффекта от использования связей можно достичь только при выполнении операции соединения двух кластеризованных по этой связи отношений, если поле соединения совпадает с полем связывания, и условия, накладываемые на родительское отношение, выделяют в нем ровно один кортеж. Очевидно, что такие запросы на практике редки. (Отметим, что приведенные соображения принадлежат автору и не излагались в публикациях по System R, так что на самом деле причины могли быть и другими.)
Кроме отношений и индексов при работе System R на внешней памяти могут располагаться еще и временные объекты - списки (lists). Список - это мгновенный снимок некоторой выборки с проекцией кортежей одного отношения, возможно, упорядоченный в соответствии со значениями некоторых полей. Средства работы со списками имеются в интерфейсе RSS, но их, естественно, нет в SQL. Соответственно, эти средства используются только внутри системы при выполнении запросов (в частности, один из наиболее эффективных алгоритмов выполнения соединений основан на использовании отсортированных списков кортежей). Публикации по System R не дают точного представления о структурах данных, используемых при организации списков, но исходя из здравого смысла можно предположить, что они устроены не так, как отношения (например, для кортежа, входящего в список, не требуется адресация через tid), и что располагаются они во временных файлах (в случае сбоя системы все временные объекты пропадают).