Ядро Mach имеет мощную, тщательно разработанную и в высшей степени гибкую систему управления памятью, основанную на страничном механизме и обладающую многими редкими свойствами. В частности, в нем машинно-зависимая часть кода отделена от машинно-независимой части чрезвычайно ясным и необычным способом. Это разделение делает управление памятью более мобильным, чем в других системах. Кроме того, система управления памятью тесно взаимодействует с коммуникационной системой.
Одной из основных особенностей системы управления памятью Mach является то, что ее код разбит на три части. Первая часть называется pmap, который работает в ядре и занимается работой с устройством отображения виртуальных адресов в физические (Memory Management Unit, MMU). Эта часть устанавливает значения регистров MMU и аппаратных страничных таблиц, а также перехватывает все страничные прерывания. Эта часть кода зависит от архитектуры MMU и должна быть переписана для каждой новой машины всякий раз, когда Mach на нее переносится. Вторая часть - это машинно-независимый код ядра, и он связан с обработкой страничных сбоев, управляет отображением областей памяти и заменой страниц.
Третья часть кода работает в пользовательском пространстве в качестве процесса, называемого "менеджер памяти" (memory manager) или иногда "внешний менеджер страниц" (external pager). Эта часть имеет дело с логическими аспектами (в отличие от физических) системы управления памятью, в основном, с управлением хранения образов памяти на диске. Например, менеджер памяти отслеживает информацию о том, какие виртуальные страницы используются, какие находятся в оперативной памяти и где они хранятся на диске, когда не находятся в оперативной памяти. Ядро и менеджер памяти взаимодействуют с помощью хорошо определенного протокола, что дает возможность для пользователей ядра Mach писать свои собственные менеджеры памяти. Такое разделение обязанностей позволяет реализовывать страничные системы специльного назначения. При этом ядро становится потенциально меньше и проще, так как значительная часть кода работает в пользовательском пространстве. С другой стороны, это и источник усложнения ядра, так как при этом оно должно защищать себя от ошибок или некорректной работы менеджера памяти. Кроме того, при наличии двух активных частей системы управления памятью возможно возникновение гонок между ними.
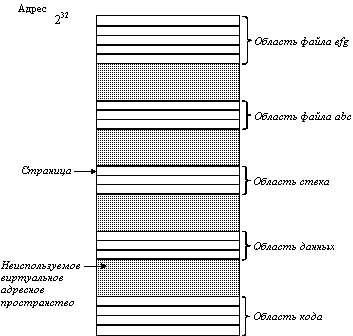
Концептуально модель памяти в Mach выглядит для пользовательских процессов в виде большого линейного виртуального адресного пространства. Для большинства 32-х разрядных процессоров адресное пространство занимает диапазон от 0 до 232 - 1 (4 Гбайта). Адресное пространство поддерживается страничным механизмом.
Mach обеспечивает очень тонкое управление механизмом использования виртуальных страниц (для тех процессов, которые интересуются этим). Для начала скажем о том, что адресное пространство может использоваться разреженным способом. Например, процесс может иметь дюжину секций виртуального адресного пространства, каждая из которых находится на расстоянии сотен мегабайт от ближайшего соседа, с большими зазорами неиспользуемого адресного пространства между этими секциями.
Теоретически любое виртуальное адресное пространство может быть разреженным, так что способность использовать большое количество разбросанных секций не является в действительности свойством архитектуры виртуальной памяти. Другими словами, любая 32-х битная машина должна позволять процессу иметь 50 000 секций данных, разделенных промежутками по 100 Мбайт, в пределах от 0 до 4 Гбайт. Однако, во многих реализациях линейная страничная таблица от 0 до самой старшей используемой страницы хранится в памяти ядра. На машине с размером страницы в 1 Kб эта конфигурация требует 4 миллиона элементов таблицы страниц, делая такую схему очень дорогой, если не невозможной. Даже при многоуровневой организации страничной таблицы такая разреженность в лучшем случае неприемлема. В ядре Mach при его разработке изначально ставилась задача полной поддержки разреженных адресных пространств.
Для того, чтобы определить, какие виртуальные адреса используются, а какие нет, Mach обеспечивает способ назначения и отмены секций виртуального адресного пространства, называемых областями (regions). В вызове для назначения области можно определить базовый адрес и размер, и область выделяется там, где это указано. В другом случае может быть задан только размер области, а система сама находит подходящий диапазон адресов и возвращает базовый адрес. Виртуальный адрес является действительным только в том случае, когда он попадает в назначенный диапазон. Попытка использовать адрес из промежутков между назначенными областями вызывает прерывание, которое может быть перехвачено самим процессом, если он этого пожелает.
Рис. 6.5. Адресное пространство с назначенными областями,
отображенными объектами и неиспользуемыми адресами
Ключевым понятием, связанным с использованием виртуального адресного пространства, является объект памяти (memory object). Объект памяти может быть страницей или набором страниц, а также может быть файлом или другой, более специальной, структурой данных, например, записью базы данных. Объект памяти может быть отображен в неиспользуемую часть виртуального адресного пространства, формируя новую область, как это показано на рисунке 6.5. Когда файл отображен в виртуальное адресное пространство, то его можно читать или в него можно писать с помощью обычных машинных команд. Отображенные (mapped) файлы постранично вытесняются из памяти обычным образом. Когда процесс завершается, то его отображенные в память файлы автоматически возвращаются в файловую систему вместе со всеми изменениями, произошедшими с их содержанием в то время, когда они были отображены в память. Также возможно отменить отображение файла или другого объекта памяти, освобождая его адресное пространство и делая его доступным для последовательного его распределения или отображения.
Конечно, отображение файлов в память не единственный способ доступа к ним. Их содержимое можно читать и обычным способом. Однако и в этом случае библиотечные функции могут отображать файлы в память помимо желания пользователя, а не использовать систему ввода-вывода. Такой способ позволяет страницам файлов использовать систему виртуальной памяти, а не специально выделенные буфера где-либо в системе.
Mach поддерживает некоторое количество вызовов для работы с виртуальным адресным пространством. Основные приведены в таблице 6.3. Они не являются истинными системными вызовами. Вместо этого все они используют запись сообщения в порт процесса для вызова соответствующих функций ядра.
Таблица 6.3.
Примитивы для управления виртуальным адресным пространством
| Вызов | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Allocate | Делает область виртуального адресного пространства используемой | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Deallocate | Освобождает область виртуального адресного пространства | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Map | Отображает объект памяти в виртуальное пространство | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Copy | Копирует область в другой диапазон виртуальных адресов | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Inherit | Устанавливает атрибут наследования для области | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Read | Читает данные из адресного пространства другого процесса | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Write | Записывает данные в адресное пространство другого процесса | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Первый вызов, Allocate, делает область виртуальных адресов используемой. Процесс может наследовать назначенное адресное пространство, а может и назначить дополнительное, но любая попытка обратиться к неназначенному адресу будет вызывать ошибку. Второй вызов, Deallocate, освобождает область (то есть удаляет ее из карты памяти), что дает возможность назначить ее заново или отобразить что-нибудь в нее, используя вызов Map.
Вызов Copy копирует объект памяти в новую область. Оригинальная область остается неизменной. Операция Copy выполняется оптимизированным способом с использованием разделяемых страниц, чтобы избежать физического копирования.
Вызов Inherit влияет на способ наследования областью свойств при создании нового процесса. Адресное пространство может быть сконфигурировано так, что некоторые области будут наследовать свойства, а некоторые нет. Это будет обсуждаться ниже.
Вызовы Read и Write позволяют нити получить доступ к виртуальной памяти, относящейся к другому процессу. Эти вызовы требуют, чтобы вызывающая нить имела права доступа к порту другого процесса, которые процесс может предоставить, если захочет этого.
В дополнение к вызовам, перечисленным в таблице 6.3, существует несколько других. Эти вызовы связаны, в основном, с установкой и чтением атрибутов, режимами защиты и различными видами статистической информации.
Разделение играет важную роль в Mach. Для разделения объектов нитями одного процесса никаких специальных механизмов не требуется: все они автоматически видят одно и то же адресное пространство. Если одна из них имеет доступ к части данных, то и все его имеют. Более интересной является возможность разделять двумя или более процессами одни и те же объекты памяти, или же просто разделять страницы памяти для этой цели. Иногда разделение полезно в системах с одним процессором. Например, в классической задаче производитель-потребитель может быть желательным реализовать производителя и потребителя разными процессами, но иметь общий буфер, в который производитель мог бы писать, а потребитель - брать из него данные.
В многопроцессорных системах разделение объектов между процессами часто более важно, чем в однопроцессорных. Во многих случаях задача решается за счет работы взаимодействующих процессов, работающих параллельно на разных процессорах (в отличие от разделения во времени одного процессора). Этим процессам может понадобиться непрерывный доступ к буферам, таблицам или другим структурам данных, для того, чтобы выполнить свою работу. Существенно, чтобы ОС позволяла такой вид разделения. Ранние версии UNIX'а не предоставляли такой возможности, хотя потом она была добавлена.
Рассмотрим, например, систему, которая анализирует оцифрованные спутниковые изображения Земли в реальном масштабе времени, в том темпе, в каком они передаются со спутника. Такой анализ требует больших затрат времени, и одно и то же изображение может проверяться на возможность его использования в предсказании погоды, урожая или отслеживании загрязнения среды. Каждое полученное изображение сохраняется как файл.
Для проведения такого анализа можно использовать мультипроцессор. Так как метеорологические, сельскохозяйственные и экологические программы очень отличаются друг от друга и разрабатываются различными специалистами, то нет причин делать их нитями одного процесса. Вместо этого каждая программа является отдельным процессом, который отображает текущий снимок в свое адресное пространство, как показано на рисунке 6.6. Заметим, что файл, содержащий снимок, может быть отображен в различные виртуальные адреса в каждом процессе. Хотя каждая страница только один раз присутствует в памяти, она может оказаться в картах страниц различных процессов в различных местах. С помощью такого способа все три процесса могут работать над одним и тем же файлом в одно и то же время.
Другой важной областью разделяемости является создание процессов. Как и в UNIX'е, в Mach основным способом создания нового процесса является копирование существующего процесса. В UNIX'е копия всегда является двойником процесса, выполнившего системный вызов FORK в то время как в Mach потомок может быть двойником другого процесса (прототипа).
Одним из способов создания процесса-потомка состоит в копировании всех необходимых страниц и отображения копий в адресное пространство потомка. Хотя этот способ и работает, но он необоснованно дорог. Коды программы обычно используются в режиме только-для-чтения, так что их нельзя изменять, часть данных также может использоваться в этом режиме. Страницы с режимом только-для-чтения нет необходимости копировать, так как отображение их в адресные пространства обоих процессов выполнит необходимую работу. Страницы, в которые можно писать, не всегда могут разделяться, так как семантика создания процесса (по крайней мере в UNIX) говорит, что хотя в момент создания родительский процесс и процесс-потомок идентичны, последовательные изменения в любом из них невидимы в другом адресном пространстве.
Кроме этого, некоторые области (например, определенные отображенные файлы) могут не понадобиться процессу-потомку. Зачем связываться с массой забот, связанных с отображением, если эти области просто не нужны?
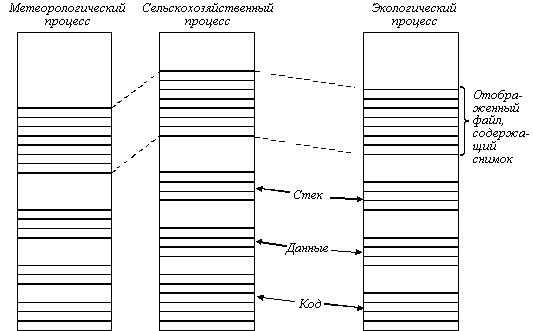
Рис. 6.6. Три процесса, разделяющие отображенный файл
Для обеспечения гибкости Mach позволяет процессу назначить атрибут наследования каждой области в адресном пространстве. Различные области могут иметь различные значения атрибута. Предусмотрены три значения атрибута:
Если область имеет первое значение, то в процессе-потомке она отсутствует. Ссылки на нее рассматриваются как и любые другие ссылки на неназначенную процессу память - они вызывают прерывания. Потомок может назначить эту область для своих собственных целей, или отобразить в нее объект памяти.
Второй вариант представляет собой истинное разделение памяти. Страницы области присутствуют как в адресном пространстве прототипа, так и потомка. Изменения, сделанные в одном пространстве, видны в другом. Этот вариант не используется при реализации системного вызова FORK, но часто бывает полезен для других целей.
Третья возможность - копирование всех страниц области и отображение копий в адресное пространство потомка. FORK использует этот вариант. В действительности Mach не выполняет реального копирования страниц, а использует вместо этого стратегию, называемую копирование-при-записи (copy-on-write). Она состоит в том, что все необходимые страницы помещаются в карту виртуальной памяти потомка, но помечаются при этом как предназначенные только для чтения, как это показано на рисунке 6.7. Пока потомок только читает из этих страниц, все работает замечательно.
Однако, если потомок пытается писать в одну из этих страниц, происходит прерывание по защите памяти. Затем операционная система делает копию этой страницы и отображает копию в адресное пространство потомка, заменяя ей защищенную от записи страницу. Новая страница помечается как доступная для чтения и записи. На рисунке 6.7, б потомок пытается произвести запись в страницу 7. Это действие приводит к тому, что страница 7 копируется в страницу 8, а страница 8 отражается в адресное пространство вместо страницы 7. Страница 8 помечается для чтения и записи, так что запись в нее не вызовет прерывание.
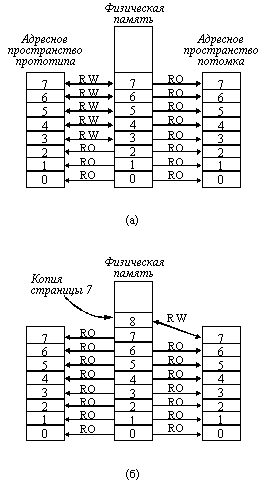
Рис. 6.7. Операция "копирование-при-записи"
а - после вызова FORK все страницы потомка помечаются "только-для-чтения"
б - при записи потомка в страницу 7 делается ее копия
Механизм копирование-при-записи имеет несколько преимуществ по сравнению со способом прямого копирования всех страниц в момент создания нового процесса. Во-первых, некоторые страницы имеют режим только-для-чтения, поэтому в их копировании нет необходимости. Во-вторых, к другим страницам обращений может никогда и не быть, поэтому, хотя потенциально в них может производиться запись, копировать их также не нужно. В третьих, хотя некоторые страницы и доступны для записи, но процесс-потомок может удалить их из своего адресного пространства, не использовав. Поэтому при использовании описанного механизма копируются только те страницы, копирование которых необходимо.
Механизм копирование-при-записи обладает и недостатками. С одной стороны, он требует более сложного администрирования, так как система должна хранить информацию о том, какие страницы действительно защищены от записи (так что обращение к ним является ошибкой), а какие нужно копировать при записи. С другой стороны, копирование-при-записи приводит к большому количеству прерываний ядра, по одному на каждую страницу, в которую происходит запись. В зависимости от аппаратуры, одно прерывание ядра, сопровождаемое копированием большого количества страниц, может оказаться эффективнее, чем многочисленные прерывания ядра, свойственные механизму копирование-при-записи. Наконец, механизм копирование-при-записи плохо работает через сеть, потому что в этом случае всегда (то есть при доступе к разделяемым страницам) нужен физический транспорт, так что преимущество этого механизма, связанное с невыполнением копирования только читаемых данных, теряется.
В начале нашего обсуждения средств управления памятью в Mach мы кратко упомянули о менеджерах памяти пользовательского режима. Теперь рассмотрим их более детально. Каждый объект памяти, который отображается в адресное пространство процесса, должен иметь внешний менеджер памяти, который им управляет. Объекты памяти различных классов управляются различными менеджерами памяти. Каждый из них может реализовывать свою собственную семантику, может решать, где хранить данные страниц, которые не находятся в физической памяти, и следовать своим собственным правилам при решении вопроса о том, что делать с объектами после того, как их отображение в память отменяется.
Для того, чтобы отобразить какой-либо объект в адресное пространство процесса, этот процесс посылает сообщение менеджеру памяти, запрашивая операцию отображения. Для того, чтобы выполнить эту работу, нужны три порта. Первый, порт объекта (object port), создается менеджером памяти и используется в дальнейшем ядром для информирования менеджера памяти о страничных отказах и других событиях, связанных с объектом. Второй порт, порт управления, создается самим ядром, так что менеджер памяти может реагировать на эти события (многие из них требуют проведения некоторых действий менеджером памяти). Использование различных портов связано с тем, что порты являются однонаправленными. В порт объекта пишет ядро, а читает менеджер памяти, а порт управления работает в обратном направлении.
Третьим является порт имени (name port), который используется как разновидность имени, с помощью которого идентифицируется объект. Например, нить может передать ядру виртуальный адрес и спросить, к какой области он относится. Ответом будет указатель на порт имени. Если адреса относятся к одной и той же области, то они будут идентифицироваться одним и тем же портом имени.
Когда менеджер памяти отображает объект, он обеспечивает создание порта объекта как одного из параметров. Затем ядро создает два других порта и посылает инициализирующее сообщение на порт объекта, несущее информацию о портах управления и имени. Затем менеджер памяти посылает ответ, сообщая ядру о том, какими являются атрибуты объекта, а также о том, нужно или нет хранить объект в кэше после того, как отображение будет отменено. Изначально все страницы объекта помечаются как запрещенные по чтению и записи, чтобы вызвать прерывание при первом использовании.
В этом месте менеджер памяти выполняет чтение порта объекта и блокирует себя. Нить, которая отобразила объект, с этого момента разблокируется и может выполняться. Менеджер памяти простаивает до тех пор, пока ядро не попросит его что-либо сделать, записав сообщение в порт объекта.
Раньше или позже, нить несомненно попытается прочитать страницу или записать в страницу, относящуюся к объекту памяти. Ядро при этом пошлет сообщение менеджеру памяти через порт объекта, информируя его о том, к какой странице произошло обращение, и попросит менеджер обеспечить эту страницу. Это сообщение является асинхронным, так как ядро не решается заблокировать любую из своих нитей в ожидании ответа от пользовательского процесса, которого может и не быть. Во время ожидания ответа ядро приостанавливает вызвавшую обращение к странице нить и ищет другие нити для выполнения.
Когда менеджер памяти узнает о страничном отказе, он проверяет, является ли обращение разрешенным. Если нет, то он посылает ядру сообщение об ошибке. Если же отображение разрешено, менеджер памяти получает страницу тем методом, который подходит для этого объекта. Если объект является файлом, то менеджер памяти ищет корректный адрес и читает страницу в собственное адресное пространство. Затем он посылает ответ ядру, снабжая его указателем на эту страницу.
Ядро отображает страницу в адресное пространство вызвавшего обращение процесса. Теперь нить может быть разблокирована. Этот процесс повторяется до тех пор, пока все нужные страницы не загрузятся.
Чтобы быть уверенным в том, что существует необходимый запас свободных страничных кадров, нить страничного демона время от времени просыпается и проверяет состояние памяти. Если свободных страничных кадров физической памяти недостаточно, то она собирает информацию о старых "грязных" страницах и отсылает ее менеджеру памяти, ответственному за объект, которому принадлежат страницы. Ожидается, что менеджер памяти запишет эти страницы на диск и сообщит, когда эта операция будет завершена. Если страница относится к файлу, то менеджер сначала найдет смещение страницы в файле, а затем запишет ее туда. Используемый при этом алгоритм замены - это второй вопрос.
Стоит заметить, что страничный демон является частью ядра. Хотя алгоритм замены страниц полностью машинно-независим, в ситуации, когда память заполнена страницами, которые управляются разными менеджерами, нет приемлемого способа разрешить одному из них принимать решение о том, какую страницу нужно вытеснить из памяти. Единственным приемлемым способом является статическое распределение страничных кадров между различными менеджерами и разрешение каждому из них заменять страницы в пределах этого набора. Однако из-за того, что глобальный алгоритм, вообще говоря, более эффективен, чем локальный, такой подход не используется.
В дополнение к особым менеджерам памяти, которые отображают файлы и другие специальные объекты, имеется менеджер памяти "по умолчанию" (default) для "обычного" отображения страниц. Когда процесс просит выделить ему область виртуального адресного пространства с помощью вызова Allocate, то фактически происходит отображение объекта, управляемого менеджером памяти "по умолчанию". Этот менеджер поставляет заполненные нулями страницы, если это необходимо. Он использует временный файл для образования пространства на диске для свопинга страниц, а не специальную область на диске, как это делается в UNIX'е.
Чтобы концепция внешнего менеджера памяти заработала, должен существовать и использоваться строго определенный протокол взаимодействия между ядром и менеджером памяти. Этот протокол состоит из небольшого количества типов сообщений, которыми обмениваются ядро и менеджер. Любое взаимодействие между ними инициируется ядром в форме асинхронных сообщений, посылаемых в порт объекта некоторого объекта памяти. В ответ на него менеджер посылает асинхронный ответ на порт управления.
В таблице 6.4 приведен список типов сообщений, которые ядро посылает менеджеру памяти.
Таблица 6.4.
Некоторые типы сообщений, посылаемых ядром менеджеру сообщений
| Вызов | Описание | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Init | Инициализировать новый отображенный в память объект | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Data_request | Передать ядру определенную страницу для обработки страничного отказа | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Data_write | Взять страницу из памяти и переписать ее | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Data_unlock | Разблокирует страницу, так что ядро может ее использовать | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Lock_completed | Завершено выполнение предшествующий запрос Lock_request | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Terminate | Информирование о том, что данный объект больше не используется | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Когда объект отображается в память с использованием вызова Map, то ядро посылает сообщение Init соответствующему менеджеру памяти, чтобы позволить ему инициализировать себя. Это сообщение определяет порты, которые должны будут использоваться позже в диалоге с объектом. Запросы от ядра на получение страницы и поставку страницы осуществляются с помощью вызовов Data_request и Data_write соответственно. Эти сообщения управляют трафиком страниц в обоих направлениях, и поэтому являются наиболее важными вызовами.
Сообщение Data_unlock представляет собой запрос от ядра менеджеру памяти на разблокирование заблокированной страницы, так что ядро может использовать ее для другого процесса. Сообщение Lock_completed оповещает о завершении последовательности Lock_request, и будет рассмотрен ниже. Наконец, сообщение Terminate сообщает менеджеру памяти, что объект, имя которого указано в вызове, больше не используется и может быть удален из памяти. Существуют вызовы, определенные для менеджера памяти "по умолчанию".
Сообщения, перечисленные в таблице 6.5, передаются от внешнего менеджера памяти ядру.
Таблица 6.5.
Сообщения, посылаемые менеджером памяти ядру
| Вызов | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Set_attributes | Ответ на вызов Init | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Data_provided | Ответ на вызов Data_request - здесь: запрошенная страница доставлена | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Data_unavailable | Ответ на вызов - страницы нет в наличии | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Lock_request | Запрашивает ядро для выполнения очистки, вытеснения или блокировки страниц | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Destroy | Разрушить объект, который больше не нужен | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Первое сообщение, Set_attributes, является ответом на сообщение Init. Оно сообщает ядру, что менеджер готов обрабатывать вновь отображенный объект. Ответ также содержит биты режима для объекта и говорит ядру, следует или нет кэшировать объект, даже если ни один процесс в какой-либо момент времени не отображает его. Следующие два сообщения являются ответами на сообщение Data_request. Это сообщение запрашивает страницу у менеджера памяти. Ответ менеджера зависит от того, может он предоставить страницу или нет. Первое сообщение говорит о том, что может, второе - о том, что нет.
Сообщение Lock_request позволяет менеджеру памяти попросить ядро очистить некоторые страницы, то есть послать ему эти страницы, чтобы они могли быть записаны на диск. Это сообщение может быть использовано также и для того, чтобы изменить режим защиты страниц (чтение, запись, выполнение). Наконец, сообщение Destroy служит для уведомления ядра о том, что некоторый объект больше не нужен.
Необходимо обратить внимание на то, что когда ядро посылает сообщение менеджеру памяти, оно в действительности выполняет вызов. Хотя при этом способе гибкость повышается, некоторые разработчики систем считают, что это неэлегантно - ядру вызывать пользовательский процесс для выполнения для ядра некоторого сервиса. Эти люди обычно верят в иерархические системы, когда нижние уровни обеспечивают сервис для верхних, а не наоборот.
Концепция внешних менеджеров памяти в Mach хорошо подходит для реализации распределенной страничной разделяемой памяти. В этом разделе будут кратко описаны некоторые из работ, выполненные в этой области. Основная идея состоит в том, чтобы получить единое, линейное виртуальное адресное пространство, которое разделяется между процессами, работающими на компьютерах, которые не имеют какой-либо физической разделяемой памяти. Когда нить ссылается на страницу, которой у нее нет, то происходит страничное прерывание. Требуемая страница отыскивается на одном из дисков сети, доставляется на ту машину, где произошел страничный сбой, и помещается в физическую память, так что нить может продолжать работать.
Так как Mach уже имеет менеджеры памяти для различных классов объектов, то естественно ввести новый объект памяти - разделяемую страницу. Разделяемые страницы управляются одним или более специальными менеджерами памяти. Одной из возможностей является существование единого менеджера памяти, который управляет всеми разделяемыми страницами. Другой вариант состоит в том, что для каждой разделяемой страницы или набора разделяемых страниц используется свой менеджер памяти, чтобы распределить нагрузку.
Еще одна возможность состоит в использовании различных менеджеров памяти для страниц с различной семантикой. Например, один менеджер памяти мог бы гарантировать полную согласованность памяти, означающую, что любое чтение, следующее за записью, всегда будет видеть самые свежие данные. Другой менеджер памяти мог бы предоставлять более слабую семантику, например, что чтение никогда не возвращает данные, которые устарели более, чем на 30 секунд.
Рассмотрим наиболее общий случай: одна разделяемая страница, централизованное управление и полная согласованность памяти. Все остальные страницы локальны для каждой отдельной машины. Для реализации этой модели нам понадобится один менеджер памяти, который обслуживает все машины системы. Назовем его сервером распределенной разделяемой памяти (Distributed Shared Memory, DSM). DSM-сервер обрабатывает ссылки на разделяемую страницу. Обычные менеджеры памяти управляют остальными страницами. До сих пор мы молчаливо подразумевали, что менеджер или менеджеры памяти, которые обслуживают данную машину, должны быть локальными для этой машины. Фактически, из-за того, что коммуникации прозрачны в Mach, менеджер памяти не обязательно располагается на той машине, чьей памятью он управляет.
Разделяемая страница всегда доступна для чтения или записи. Если она доступна для чтения, то она может копироваться (реплицироваться) на различные машины. Если же она доступна для записи, то должна быть только одна ее копия. DSM-сервер всегда знает состояние разделяемой страницы, а также на какой машине или машинах она в настоящий момент находится. Если страница доступна для чтения, то DSM-сервер сам имеет ее действительную копию.
Предположим, что страница является доступной для чтения, и нить, работающая на какой-то машине, пытается ее прочитать. DSM-сервер просто посылает этой машине копию страницы, обновляет свои таблицы, чтобы зафиксировать еще одного читателя, и завершает на этом данную работу. Страница будет отображена в новой машине и помечена "для чтения".
Теперь предположим, что один из читателей пытается осуществить запись в эту страницу. DSM-сервер посылает сообщение ядру или ядрам, которые имеют эту страницу, с просьбой вернуть ее. Сама страница не должна передаваться, так как DSM-сервер имеет ее действительную копию. Все, что требуется, это подтверждение, что страница больше не используется. После того, как все ядра освободят страницу, писатель получает ее копию вместе с разрешением использовать ее для записи.
Если теперь кто-либо еще хочет использовать эту страницу (которая теперь доступна для записи), DSM-сервер говорит текущему ее владельцу, что ее нужно прекратить использовать и вернуть. Когда страница возвращается, она может быть передана одному или нескольким читателям или одному писателю. Возможны многие вариации этого централизованного алгоритма, например, не запрашивать возвращение страницы до тех пор, пока машина, владеющая ею, не попользуется в течение некоторого минимального времени. Возможно также и распределенное решение.