| United States-English |
|
|
|
Managing Serviceguard Fifteenth Edition > Chapter 2 Understanding
Serviceguard Hardware ConfigurationsRedundant Disk Storage |
|
Each node in a cluster has its own root disk, but each node is also physically connected to several other disks in such a way that more than one node can obtain access to the data and programs associated with a package it is configured for. This access is provided by a Storage Manager, such as Logical Volume Manager (LVM), or Veritas Volume Manager (VxVM) (or Veritas Cluster Volume Manager (CVM). LVM and VxVM disk storage groups can be activated by no more than one node at a time, but when a failover package is moved, the storage group can be activated by the adoptive node. All of the disks in the storage group owned by a failover package must be connected to the original node and to all possible adoptive nodes for that package. Disk storage is made redundant by using RAID or software mirroring. The following interfaces are supported by Serviceguard for disks that are connected to two or more nodes (shared data disks):
Not all SCSI disks are supported. See the HP Unix Servers Configuration Guide (available through your HP representative) for a list of currently supported disks.
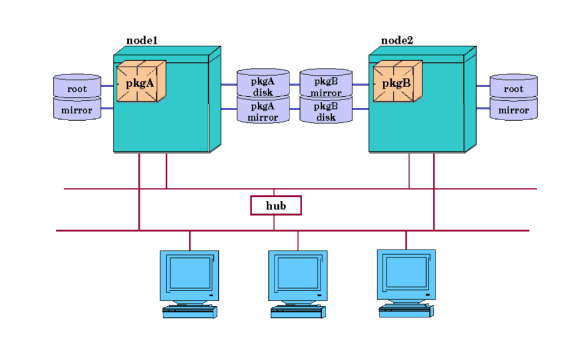
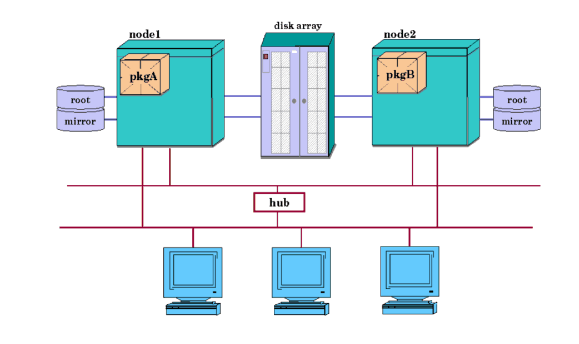
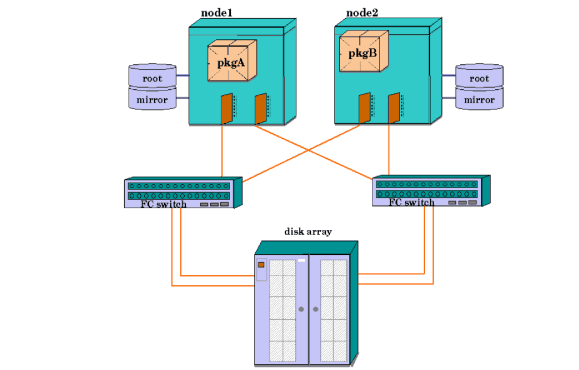
External shared Fast/Wide SCSI buses must be equipped with in-line terminators for disks on a shared bus. Refer to the “Troubleshooting” chapter for additional information. When planning and assigning SCSI bus priority, remember that one node can dominate a bus shared by multiple nodes, depending on what SCSI addresses are assigned to the controller for each node on the shared bus. All SCSI addresses, including the addresses of all interface cards, must be unique for all devices on a shared bus. It is required that you provide data protection for your highly available system, using one of two methods: Serviceguard itself does not provide protection for data on your disks, but protection is provided by HP’s Mirrordisk/UX product for LVM storage, and by the Veritas Volume Manager for VxVM and CVM. The logical volumes used for Serviceguard packages should be mirrored; so should the cluster nodes’ root disks. When you configure logical volumes using software mirroring, the members of each mirrored set contain exactly the same data. If one disk fails, the storage manager automatically keeps the data available by using the mirror. you can use three-way mirroring in LVM (or additional plexes with VxVM) to allow for online backups or to provide an additional level of high availability. To protect against Fibre Channel or SCSI bus failures, each copy of the data must be accessed by a separate bus; that is, you cannot have all copies of the data on disk drives connected to the same bus. It is critical for high availability that you mirror both data and root disks. If you do not mirror your data disks and there is a disk failure, you will not be able to run your applications on any node in the cluster until the disk has been replaced and the data reloaded. If the root disk fails, you will be able to run your applications on other nodes in the cluster, since the data is shared. But system behavior at the time of a root disk failure is unpredictable, and it is possible for an application to hang while the system is still running, preventing it from being started on another node until the failing node is halted. Mirroring the root disk allows the system to continue normal operation when a root disk failure occurs. An alternate method of achieving protection for your data is to employ a disk array with hardware RAID levels that provide data redundancy, such as RAID Level 1 or RAID Level 5. The array provides data redundancy for the disks. This protection needs to be combined with the use of redundant host bus interfaces (SCSI or Fibre Channel) between each node and the array. The use of redundant interfaces protects against single points of failure in the I/O channel, and RAID 1 or 5 configuration provides redundancy for the storage media. Multipathing is automatically configured in HP-UX 11i v3 (this is often called native multipathing), or in some cases can be configured with third-party software such as EMC Powerpath. For more information about multipathing in HP-UX 11i v3, see the white paper HP-UX 11i v3 Native Multipathing for Mass Storage, and the Logical Volume Management volume of the HP-UX System Administrator’s Guide in the HP-UX 11i v3 Operating Environments collection at http://docs.hp.com. See also “About Device File Names (Device Special Files)”. If you are using LVM, you can configure disk monitoring to detect a failed mechanism by using the disk monitor capabilities of the EMS HA Monitors, available as a separate product (B5736DA). Monitoring can be set up to trigger a package failover or to report disk failure events to a Serviceguard, to another application, or by email. For more information, refer to the manual Using High Availability Monitors (B5736-90074), available at http://docs.hp.com -> High Availability -> Event Monitoring Service and HA Monitors -> Installation and User’s Guide. Mirroring provides data protection, but after a disk failure, the failed disk must be replaced. With conventional disks, this is done by bringing down the cluster and replacing the mechanism. With disk arrays and with special HA disk enclosures, it is possible to replace a disk while the cluster stays up and the application remains online. The process is described under “Replacing Disks” in the chapter “Troubleshooting Your Cluster.” Depending on the system configuration, it is possible to replace failed disk I/O cards while the system remains online. The process is described under “Replacing I/O Cards” in the chapter “Troubleshooting Your Cluster.” Figure 2-2 “Mirrored Disks Connected for High Availability ” shows a two node cluster. Each node has one root disk which is mirrored and one package for which it is the primary node. Resources have been allocated to each node so that each node may adopt the package from the other node. Each package has one disk volume group assigned to it and the logical volumes in that volume group are mirrored. Please note that Package A’s disk and the mirror of Package B’s disk are on one interface while Package B’s disk and the mirror of Package A’s disk are on a separate bus. This arrangement eliminates single points of failure and makes either the disk or its mirror available in the event one of the buses fails. Figure 2-3 “Cluster with High Availability Disk Array ” below shows a similar cluster with a disk array connected to each node on two I/O channels. See “About Multipathing”. Details on logical volume configuration for Serviceguard are in the chapter “Building an HA Cluster Configuration.” In Figure 2-4 “Cluster with Fibre Channel Switched Disk Array”, the root disks are shown with simple mirroring, but the shared storage is now accessed via redundant Fibre Channel switches attached to a disk array. The cabling is set up so that each node is attached to both switches, and both switches are attached to the disk array with redundant links. This type of configuration uses native HP-UX or other multipathing software; see “About Multipathing”. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||