| United States-English |
|
|
|
Managing Serviceguard Fifteenth Edition > Chapter 5 Building
an HA Cluster ConfigurationConfiguring the Cluster |
|
This section describes how to define the basic cluster configuration. This must be done on a system that is not part of a Serviceguard cluster (that is, on which Serviceguard is installed but not configured).
Use the cmquerycl command to specify a set of nodes to be included in the cluster and to generate a template for the cluster configuration file.
Here is an example of the command (enter it all one line): cmquerycl -v -C $SGCONF/clust1.config -n ftsys9 -n ftsys10 This creates a template file, by default /etc/cmcluster/clust1.config. In this output file, keywords are separated from definitions by white space. Comments are permitted, and must be preceded by a pound sign (#) in the far left column.
The cmquerycl(1m) manpage further explains the parameters that appear in the template file. Many are also described in the “Planning” chapter. Modify your /etc/cmcluster/clust1.config file as needed. In a larger or more complex cluster with many nodes, networks or disks, the cmquerycl command may take several minutes to complete. To speed up the configuration process, you can direct the command to return selected information only by using the -k and -w options: -k eliminates some disk probing, and does not return information about potential cluster lock volume groups and lock physical volumes. -w local lets you specify local network probing, in which LAN connectivity is verified between interfaces within each node only. This is the default when you use cmquerycl with the -C option. (Do not use -w local if you need to discover nodes and subnets for a cross-subnet configuration; see “Full Network Probing” below.) -w none skips network querying. If you have recently checked the networks, this option will save time. -w full lets you specify full network probing, in which actual connectivity is verified among all LAN interfaces on all nodes in the cluster, whether or not they are all on the same subnet.
A cluster lock disk, lock LUN, or quorum server, is required for two-node clusters. The lock must be accessible to all nodes and must be powered separately from the nodes. See “Cluster Lock” in Chapter 3 for additional information. To create a lock disk, enter the lock disk information following the cluster name. The lock disk must be in an LVM volume group that is accessible to all the nodes in the cluster. The default FIRST_CLUSTER_LOCK_VG and FIRST_CLUSTER_LOCK_PV supplied in the ASCII template created with cmquerycl are the volume group and physical volume name of a disk connected to all cluster nodes; if there is more than one, the disk is chosen on the basis of minimum failover time calculations. You should ensure that this disk meets your power wiring requirements. If necessary, choose a disk powered by a circuit which powers fewer than half the nodes in the cluster. To display the failover times of disks, use the cmquerycl command, specifying all the nodes in the cluster. The output of the command lists the disks connected to each node together with the re-formation time associated with each. Do not include the node’s entire domain name; for example, specify ftsys9, not ftsys9.cup.hp.com:
cmquerycl will not print out the re-formation time for a volume group that currently belongs to a cluster. If you want cmquerycl to print the re-formation time for a volume group, run vgchange -c n <vg name> to clear the cluster ID from the volume group. After you are done, do not forget to run vgchange -c y vgname to re-write the cluster ID back to the volume group; for example: vgchange -c y /dev/vglock
If your configuration requires you to configure a second cluster lock, enter the following parameters in the cluster configuration file:
where the /dev/volume-group is the name of the second volume group and block-special-file is the physical volume name of a lock disk in the chosen volume group. These lines should be added for each node; for example:
or (using agile addressing; see “About Device File Names (Device Special Files)”):
See also “Choosing Cluster Lock Disks”. A cluster lock disk, lock LUN, or quorum server, is required for two-node clusters. The lock must be accessible to all nodes and must be powered separately from the nodes. See “Cluster Lock” and “Setting Up a Lock LUN” for more information. To specify a lock LUN in the cluster configuration file, enter the lock LUN information following each node name, for example: NODE_NAME hasupt21 NETWORK_INTERFACE lan1 HEARTBEAT_IP 15.13.173.189 NETWORK_INTERFACE lan2 NETWORK_INTERFACE lan3 CLUSTER_LOCK_LUN /dev/dsk/c0t1d1A cluster lock disk, lock LUN, or quorum server, is required for two-node clusters. To obtain a cluster configuration file that includes Quorum Server parameters, use the -q option of the cmquerycl command, specifying a Quorum Server host server, for example (all on one line): cmquerycl -q <QS_Host> -n ftsys9 -n ftsys10 -C <ClusterName>.config Enter the QS_HOST, QS_POLLING_INTERVAL and optionally a QS_TIMEOUT_EXTENSION. To specify an alternate hostname or IP address by which the Quorum Server can be reached, use a command such as (all on one line): cmquerycl -q <QS_Host> <QS_Addr> -n ftsys9 -n ftsys10 -C <ClusterName>.config For detailed discussion of these parameters, see “Configuring Serviceguard to Use the Quorum Server” in the HP Serviceguard Quorum Server Version A.03.00 Release Notes, at http://www.docs.hp.com -> High Availability -> Quorum Server. As of Serviceguard A.11.18 it is possible to configure multiple subnets, joined by a router, both for the cluster heartbeat and for data, with some nodes using one subnet and some another. See “Cross-Subnet Configurations” for rules and definitions. You must use the -w full option to cmquerycl to discover the available subnets. For example, assume that you are planning to configure four nodes, NodeA, NodeB, NodeC, and NodeD, into a cluster that uses the subnets 15.13.164.0, 15.13.172.0, 15.13.165.0, 15.13.182.0, 15.244.65.0, and 15.244.56.0. The following command
will produce the output such as the following: Node Names: nodeA nodeB nodeC nodeDBridged networks (full probing performed):1 lan3 (nodeA) lan4 (nodeA) lan3 (nodeB) lan4 (nodeB) 2 lan1 (nodeA) lan1 (nodeB) 3 lan2 (nodeA) lan2 (nodeB) 4 lan3 (nodeC) lan4 (nodeC) lan3 (nodeD) lan4 (nodeD) 5 lan1 (nodeC) lan1 (nodeD)
6 lan2 (nodeC) lan2 (nodeD) IP subnets: IPv4: 15.13.164.0 lan1 (nodeA) lan1 (nodeB)
15.13.172.0 lan1 (nodeC) lan1 (nodeD)
15.13.165.0 lan2 (nodeA) lan2 (nodeB)
15.13.182.0 lan2 (nodeC) lan2 (nodeD)
15.244.65.0 lan3 (nodeA) lan3 (nodeB)
15.244.56.0 lan4 (nodeC) lan4 (nodeD) IPv6: 3ffe:1111::/64 lan3 (nodeA) lan3 (nodeB) 3ffe:2222::/64 lan3 (nodeC) lan3 (nodeD) Possible Heartbeat IPs: 15.13.164.0 15.13.164.1 (nodeA) 15.13.164.2 (nodeB) 15.13.172.0 15.13.172.158 (nodeC) 15.13.172.159 (nodeD) 15.13.165.0 15.13.165.1 (nodeA) 15.13.165.2 (nodeB) 15.13.182.0 15.13.182.158 (nodeC) 15.13.182.159 (nodeD) Route connectivity(full probing performed): 1 15.13.164.0 15.13.172.0 2 15.13.165.0 15.13.182.0 3 15.244.65.0 4 15.244.56.0 In the Route connectivity section, the numbers on the left (1-4) identify which subnets are routed to each other (for example 15.13.164.0 and 15.13.172.0).
For information about configuring the heartbeat in a cross-subnet configuration, see the HEARTBEAT_IP parameter discussion under “Cluster Configuration Parameters” starting on “Cluster Configuration Parameters ”. The cluster configuration file includes entries for IP addresses on the heartbeat subnet. HP recommends that you use a dedicated heartbeat subnet, and configure heartbeat on other subnets as well, including the data subnet. The heartbeat must be on an IPv4 subnet and must employ IPv4 addresses. An IPv6 heartbeat is not supported. The heartbeat can comprise multiple subnets joined by a router. In this case at least two heartbeat paths must be configured for each cluster node. See also the discussion of HEARTBEAT_IP under “Cluster Configuration Parameters ” starting on “Cluster Configuration Parameters ”, and “Cross-Subnet Configurations”.
This specifies the most packages that can be configured in the cluster. The parameter value must be equal to or greater than the number of packages currently configured in the cluster. The count includes all types of packages: failover, multi-node, and system multi-node. As of Serviceguard A.11.17, the default is 150, which is the maximum allowable number of packages in a cluster.
The cmquerycl command supplies default cluster timing parameters for HEARTBEAT_INTERVAL and NODE_TIMEOUT. Changing these parameters will directly affect the cluster’s reformation and failover times. It is useful to modify these parameters if the cluster is re-forming occasionally because of heavy system load or heavy network traffic; you can do this while the cluster is running. The default value of 2 seconds for NODE_TIMEOUT leads to a best case failover time of 30 seconds. If NODE_TIMEOUT is changed to 10 seconds, which means that the cluster manager waits 5 times longer to timeout a node, the failover time is increased by 5, to approximately 150 seconds. NODE_TIMEOUT must be at least twice HEARTBEAT_INTERVAL. A good rule of thumb is to have at least two or three heartbeats within one NODE_TIMEOUT. For more information about node timeouts, see “What Happens when a Node Times Out” and the HEARTBEAT_INTERVAL and NODE_TIMEOUT parameter discussions under “Cluster Configuration Parameters ” starting on “Cluster Configuration Parameters ”. Serviceguard Extension for Faster Failover (SGeFF) is a separately purchased product. If it is installed, the configuration file will display the parameter to enable it. SGeFF reduces the time it takes Serviceguard to process a failover. It cannot, however, change the time it takes for packages and applications to gracefully shut down and restart. SGeFF has requirements for cluster configuration, as outlined in the cluster configuration template file. For more information, see the Serviceguard Extension for Faster Failover Release Notes posted on http://www.docs.hp.com -> High Availability. See also Optimizing Failover Time in a Serviceguard Environment at http://www.docs.hp.com -> High Availability -> Serviceguard -> White Papers. Serviceguard access-control policies define cluster users’ administrative or monitoring capabilities. Although you will also sometimes see the term role-based access (RBA) in the output of Serviceguard commands, the preferred set of terms, always used in this manual, is as follows:
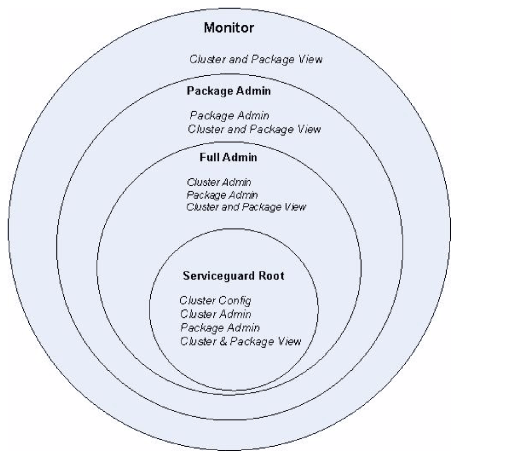
Serviceguard daemons grant access to Serviceguard commands by matching the command user’s hostname and username against the access control policies you define. Each user can execute only the commands allowed by his or her role. The diagram that shows the access roles and their capabilities. The innermost circle is the most trusted; the outermost the least. Each role can perform its own functions and the functions in all of the circles outside it. For example Serviceguard Root can perform its own functions plus all the functions of Full Admin, Package Admin and Monitor; Full Admin can perform its own functions plus the functions of Package Admin and Monitor; and so on. Serviceguard recognizes two levels of access, root and non-root:
The HP-UX root user on each cluster node is automatically granted the Serviceguard root access role on all nodes. (See “Configuring Root-Level Access” for more information.) Access-control policies define non-root roles for other cluster users.
Define access-control policies for a cluster in the cluster configuration file (see “Cluster Configuration Parameters ”), and for a specific package in the package configuration file (see “user_name”). You can define up to 200 access policies for each cluster. A root user can create or modify access control policies while the cluster is running.
Access control policies are defined by three parameters in the configuration file:
Here is an example of an access control policy: If this policy is defined in the cluster configuration file, it grants user john the PACKAGE_ADMIN role for any package on node bit. User john also has the MONITOR role for the entire cluster, because PACKAGE_ADMIN includes MONITOR.If the policy is defined in the package configuration file for PackageA, then user john on node bit has the PACKAGE_ADMIN role only for PackageA. Plan the cluster’s roles and validate them as soon as possible. If your organization’s security policies allow it, you may find it easiest to create group logins. For example, you could create a MONITOR role for user operator1 from ANY_CLUSTER_NODE. Then you could give this login name and password to everyone who will need to monitor your clusters. Do not configure different roles for the same user and host; Serviceguard treats this as a conflict and will fail with an error when applying the configuration. “Wildcards”, such as ANY_USER and ANY_SERVICEGUARD_NODE, are an exception: it is acceptable for ANY_USER and john to be given different roles.
Consider what would happen if these entries were in the cluster configuration file:
In the above example, the configuration would fail because user john is assigned two roles. (In any case, Policy 2 is unnecessary, because PACKAGE_ADMIN includes the role of MONITOR.) Policy 3 does not conflict with any other policies, even though the wildcard ANY_USER includes the individual user john.
Package configuration will fail if there is any conflict in roles between the package configuration and the cluster configuration, so it is a good idea to have the cluster configuration file in front of you when you create roles for a package; use cmgetconf to get a listing of the cluster configuration file. If a role is configured for a username/hostname in the cluster configuration file, do not specify a role for the same username/hostname in the package configuration file; and note that there is no point in assigning a package administration role to a user who is root on any node in the cluster; this user already has complete control over the administration of the cluster and its packages. Add any LVM volume groups you have configured to the cluster configuration file, with a separate VOLUME_GROUP entry for each cluster-aware volume group that will be used in the cluster. These volume groups will be initialized with the cluster ID when the cmapplyconf command is used. In addition, you should add the appropriate volume group, logical volume and filesystem information to each package that activates a volume group; see vg on “vg”.
If you have edited a cluster configuration file using the command line, use the following command to verify the content of the file:
The following items are checked:
If the cluster is online, the check also verifies that all the conditions for the specific change in configuration have been met.
After specifying all cluster parameters, apply the configuration. This action distributes the binary configuration file to all the nodes in the cluster. HP recommends doing this separately before you configure packages (as described in the next chapter) so you can verify the cluster lock, heartbeat networks, and other cluster-level operations by using the cmviewcl command on the running cluster. Before distributing the configuration, ensure that your security files permit copying among the cluster nodes. See “Preparing Your Systems” at the beginning of this chapter. Use the following steps to generate the binary configuration file and distribute the configuration to all nodes in the cluster:
The cmapplyconf command creates a binary version of the cluster configuration file and distributes it to all nodes in the cluster. This action ensures that the contents of the file are consistent across all nodes. Note that the cmapplyconf command does not distribute the ASCII configuration file.
After configuring the cluster, create a backup copy of the LVM volume group configuration by using the vgcfgbackup command for each volume group you have created. If a disk in a volume group must be replaced, you can then restore the disk's metadata by using the vgcfgrestore command. The procedure is described under “Replacing Disks” in the “Troubleshooting” chapter. Be sure to use vgcfgbackup for all volume groups, especially the cluster lock volume group.
In addition to configuring the cluster, you create the appropriate logical volume infrastructure to provide access to data from different nodes. This is done with Logical Volume Manager (LVM), Veritas Volume Manager (VxVM), or Veritas Cluster Volume Manager (CVM). You can also use a mixture of volume types, depending on your needs. LVM and VxVM configuration are done before cluster configuration, and CVM configuration is done after cluster configuration. This section has information about configuring a cluster that uses the Veritas cluster file system (CFS) with Veritas cluster volume manager (CVM) 4.1 and later. The next section (“Creating the Storage Infrastructure and Filesystems with Veritas Cluster Volume Manager (CVM)”) has information about configuring the Veritas Cluster Volume Manager (CVM) with other filesystems, not CFS. Both solutions use many of the same commands, but the processes are in a slightly different order. Another difference is that when you use CFS, Serviceguard creates packages to manage the disk groups and mount points so you do not activate CFS disk groups or CFS mount points in your application packages. Refer to the Serviceguard man pages for more information about the commands cfscluster, cfsdgadm, cfsmntadm, cfsmount and cfsumount and cmgetpkgenv. Information is also in the documentation for HP Serviceguard Storage Management Suite posted at http:// docs.hp.com -> High Availability -> HP Serviceguard Storage Management Suite.
Initialize the disk group from the master node.
The storage checkpoints and snapshots are two additional mount point package types. They can be associated with the cluster via the cfsmntadm(1m) command. The Veritas File System provides a unique storage checkpoint facility which quickly creates a persistent image of a filesystem at an exact point in time. Storage checkpoints significantly reduce I/O overhead by identifying and maintaining only the filesystem blocks that have changed since the last storage checkpoint or backup. This is done by a copy-on-write technique. Unlike a disk-based mirroring technology, which requires a separate storage space, this Veritas technology minimizes the use of disk space by creating a storage checkpoint within the same free space available to the filesystem. For more information about the technique, see the Veritas File System Administrator’s Guide appropriate to your version of CFS, posted at http://docs.hp.com. The following example illustrates how to create a storage checkpoint of the /cfs/mnt2 filesystem. Start with a cluster-mounted file system.
A snapshot is a frozen image of an active file system that does not change when the contents of target file system changes. On cluster file systems, snapshots can be created on any node in the cluster, and backup operations can be performed from that node. The snapshot of a cluster file system is accessible only on the node where it is created; the snapshot file system itself cannot be cluster mounted. For details on creating snapshots on cluster file systems, see the Veritas Storage Foundation Cluster File System Installation and Administration Guide posted at http://docs.hp.com:. The following example illustrates how to create a snapshot of the /tmp/logdata/log_files file system.
This section has information about configuring the Veritas Cluster Volume Manager without Veritas CFS (Cluster File System). The configuration may be needed to set up raw devices for Serviceguard Extension for RAC. The previous section (“Creating a Storage Infrastructure with Veritas Cluster File System (CFS)”) has information about configuring a cluster with CFS. Both solutions - with and without CFS - use many of the same commands, but the processes are in a slightly different order. Before starting, make sure the directory in which VxVM commands are stored (/usr/lib/vxvm/bin) is in your path. Once you have created the root disk group with vxinstall, you can use VxVM commands or the Veritas Storage Administrator GUI, VEA, to carry out configuration tasks. Instructions for running vxinstall are in the Veritas Installation Guide for your version. For more information, refer to the Veritas Volume Manager Administrator’s Guide for your version. Separate procedures are given below for:
For more information, including details about configuration of plexes (mirrors), multipathing, and RAID, refer to the HP-UX documentation for the Veritas Volume Manager. See the documents for HP Serviceguard Storage Management Suite posted at http://docs.hp.com. If you are about to create disk groups for the first time, you need to initialize the Volume Manager. Use the following command after installing VxVM/CVM on each node: vxinstall This displays a menu-driven program that steps you through the VxVM/CVM initialization sequence.
In order to use the Veritas Cluster Volume Manager (CVM), you need a cluster that is running with a Serviceguard-supplied CVM system multi-node package. This means that the cluster must already be configured and running before you create disk groups. Configure system multi-node and multi-node packages using the command line, not Serviceguard Manager. Once configured, these cluster-wide packages’ properties have a special tab under Cluster Properties.
Check the heartbeat configuration. The CVM 3.5 heartbeat requirement is different from version 4.1 and later:
Neither version can use Auto Port Aggregation, Infiniband, or VLAN interfaces as a heartbeat subnet. The CVM cluster volumes are managed by a Serviceguard-supplied system multi-node package which runs on all nodes at once, and cannot fail over. For CVM 3.5, Serviceguard creates the VxVM-CVM-pkg. For CVM 4.1 and later, Serviceguard creates the SG-CFS-pkg. The SG-CFS-pkg package has the following responsibilities:
The following commands create the system multi-node package that communicates cluster information to CVM:
You can confirm this using the cmviewcl command. This output shows results of the CVM 3.5 command above.
If it is not already running, start the cluster. This will automatically activate the special CVM package: cmruncl When CVM starts up, it selects a master node, and this is the node from which you must issue the disk group configuration commands. To determine the master node, issue the following command from each node in the cluster: vxdctl -c mode One node will identify itself as the master. Create disk groups from this node. You need to initialize the physical disks that will be employed in CVM disk groups. If a physical disk has been previously used with LVM, you should use the pvremove command to delete the LVM header data from all the disks in the volume group (this is not necessary if you have not previously used the disk with LVM). To initialize a disk for CVM, log on to the master node, then use the vxdiskadm program to initialize multiple disks, or use the vxdisksetup command to initialize one disk at a time, as in the following example: /usr/lib/vxvm/bin/vxdisksetup -i c4t3d4 Use the following steps to create disk groups.
Use the vxassist command to create volumes, as in the following example: vxassist -g logdata make log_files 1024m This command creates a 1024 MB volume named log_files in a disk group named logdata. The volume can be referenced with the block device file /dev/vx/dsk/logdata/log_files or the raw (character) device file /dev/vx/rdsk/logdata/log_files. Verify the configuration with the following command: vxdg list If you are using CVM with CFS, use CFS commands to create file systems on the volumes you have created; see “Creating a Storage Infrastructure with Veritas Cluster File System (CFS)”. The default CVM disk mirror detachment policy is global, which means that as soon as one node cannot see a specific mirror copy (plex), all nodes cannot see it as well. The alternate policy is local, which means that if one node cannot see a specific mirror copy, then CVM will deactivate access to the volume for that node only. The global policy is recommended, because it ensures all nodes are accessing the same current data. If you use local, it can cause problems if one node cannot update one of the mirror copies and the data on that copy goes stale. If any of the other nodes read from that mirror copy, they will read stale data. This can be avoided with the global option, because all nodes will only use the current mirror copy, so they will all read consistent data. This policy can be re-set on a disk group basis by using the vxedit command, as follows: vxedit set diskdetpolicy=[global|local] <DiskGroupName>
After creating units of storage with VxVM commands, you need to specify the CVM disk groups in each package configuration ASCII file. Use one DISK_GROUP parameter for each disk group the package will use. You also need to identify the CVM disk groups, filesystems, logical volumes, and mount options in the package control script. The package configuration process is described in detail in Chapter 6. You can use DSAU to centralize and simplify configuration and monitoring tasks. See “What are the Distributed Systems Administration Utilities?”. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||